With respect to other Machine Learning learning methods, Reinforcement learning doesn’t have a classic supervision, instead we have a reward signal.
Reward
The Reward Signal is a feedback signal, a scalar, that indicates how well an agent is doing at time .
Reinforcement Learning is based off the Reward Hypothesis which states that all objectives can be described by maximizing the Expected Cumulative Reward.
Training is affected by the decision made during the reward engineering phase, where the reward function is designed.
Reward tells the agent wheter a decision is optimal or not. The Reward function is designed by a system designer, based on measurements of the agent’s performances, ensuring that the learning agent receives the necessary feedback to correct its behaviour.
This can have many problems:
- reward shaping (Ng et al., 1999) sometimes you need to shape the reward signal to one more suitable for learning;
- reward hacking (Skalse et al., 2002) learning agents can exploit reward-specific loopholes to achieve undesired outcomes while still generating high rewards.
Notation
For any integer , we denote by the set . For any set , denotes the set of probability distribution over .
We use for the probability of some event , while is used to denote the expected value of a random variable . or similar variations are used to emphasize that the distribution for the expected value is governed by the probability distribution .
Moreover, we will write if a random variable is distributed according to a probability distribution .
Reinforcement Learning, formally
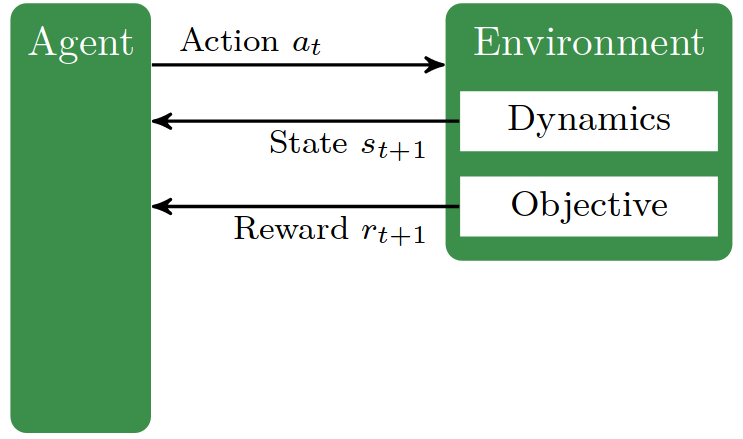
Reinforcement learning is the setting of learning behavior from rewarded interaction with the environment (Sutton & Barto, 2018). It is formalized as a Markov decision process (MDP), which is a model for sequential decision making. It iteratively:
- Observe its current state;
- Takes an action taht causes the transition to a new state;
- Receive a reward that depends on the action effectiveness.
Formally:
- is a set of states (the state space);
- is a set of actions (the action space);
- is a transition function (the transition dynamics);
- is a reward function;
- is a distribution over initial states;
- is a discount factor.
The transition function defines the dynamics of the environemnt: For any state and action is the probability of reaching after executing the action in state .
For a given state and action, the transition probability is conditionally indipendent of all previous states and action (Markov Property).
Instanteneous reward
The value of provides an immidiate evaluation after performing action in , which is called instantaneous reward1.
When both the state space and the action space are finite we call the MDP a tabular MDP.
Return
In an MDP, an -step trajectory is a sequence of pairs of state-action ending in a terminal state.
Formally, it is given by . Given and , we can define a segment which refers to a continuous sequence of steps within a larger trajectory.
A trajectory ‘s return is the accumulated (and discounted) rewards collected along this trajectory:
So the return is a projection of future reward by taking a specific series of action-states discounted by a factor that gets exponentially smaller (thus reducing how important are rewards far into the future).
The return is well defined even in the horizon is infinite as long as . If the MDP is a tabular MDP and any trajectory has finite length, i.e. is necessarily finite, we call the MDP finite, otherwise is infinite.
Policy
A policy specifies how to select actions based on the state the agent is in. Tha can be done either:
- deterministically: in this case we have a mapping from states to actions.
- stochastically: in this case we have a mapping from states to probability distributions over actions2.
RL basic loop
The basic loop consists in the agent choosing an action based on its policy and current state. As a consequence, the environment transition into the new state , governed by the transition dynamics. The agent observe the new state and the reward and the cicle starts anew.
In this setting, the RL agent aims at learning a policy that maximizes the expected return:
where the expectation is with respect to polici , transition function , and initial distribution .
Families
To solve this problem there are two different families of RL approaches:
1. Model-based RL
In this family we learn a model (i.e., ) of the underlying MDP to solve the RL problem.
2. Model-free RL
In this family we try to obtain a good policy without learning an MDP model. This family can also be divided in two sub-families:
2a. Value-based methods
(e.g. DQN)
We aim at learning the -Function of an optimal policy which is defined by
where and and in the expectation, as well as for . A policy can be designed froma -function by choosing an action in a greedy manner in each state: . Note that for deterministic optimal policy it holds that .
Similar to the action-value function , we can also define the state-value function:
Its value for some state is the expected return when starting in that state and then always using the policy . It is related to the -Function by means of
for any state .
2b. Policy-search methods
This family aims at finding a good policy in some parametrized policy space. The most data-efficient algorithms follow an actor-critic scheme where bot an actor (i.e., a policy) and a critic (i.e., a Q-value function) are learned at the same time (e.g. PPO, TD3, SAC).
In deep RL both the value functions and the policies are approxiamted with neural networks.
RL algorithms can also be further classified as on-policy or off-policy.
In the first case, such as PPO, only the recetly generated transition are used for training. In contrast, in the off-policy algorithms (such as DQN), the agent can be updated with transition non necessarily generated by its current policy.
While on-policy is usually more stable, off-policy enables mode data-efficient learning by reusing samples from a replay buffer taht stores past transitions.