Introduction
@kaufmannSurveyReinforcementLearning2024.
RLHF differs from RL in that the objective is defined and iteratevely refined by the human in the loop instead of being specified ahead of time. In fact, in conventional RL, the agent’s objective is defined by a reward function that it aims to maximize. Since engineering a good reward function is hard, learning the agent’s objective from human feedback circumvents the engineering part, and foster robust training, with the reward function dynamically refined and adjusted to distributional shifts as the agent learn.
Avoiding Reward Engineering
@kaufmannSurveyReinforcementLearning2024.
Since engineering the reward function is a hard challenge, using Human Feedback may mitigate that, enabling training agents for tasks that are hard to define manually and helping avoid safety issues that arise from misaligned rewards.
RLHF presents a promising approach to enhance alignment, however its effectiveness in resolving alignment issues is still debated (Christiano, 2023).
Notation
@kaufmannSurveyReinforcementLearning2024.
For any integer , we denote by the set . For any set , denotes the set of probability distribution over .
We use for the probability of some event , while is used to denote the expected value of a random variable . or similar variations are used to emphasize that the distribution for the expected value is governed by the probability distribution .
Moreover, we will write if a random variable is distributed according to a probability distribution .
Preference-Based MDPs
@kaufmannSurveyReinforcementLearning2024.
In contrast to standard RL (see RL formalized), RLHF doesn’t assume that a reward signal is available. It assume the existence of an oracle (e.g. human labeler) that can provide information about the reward in a specific indirect manner.
In RLHF the agent can make queries to the oracle, which in practice means asking for human feedback, and in response, the agent receives a label which in general gives a hint about the reward1.
Reward Learning
@kaufmannSurveyReinforcementLearning2024.
RLHF apporaches can be divided into two categories depending on whether a utility-based approach is used for reward modeling or an alternative criterion that is detached form a utility concept is used.
The prevalent approach is to learn a utility function from observations of pairwise comparison, which is based on the Bradley-Terry model.
The BT-model stipulates a probabilistic model for the oracle:
where means preferred to and corresponds to the utility (i.e. the return in the context of RL). For a given dataset , a utility function parameterized by can then be learned by the maximum likelihood principle (or using a cross-entropy loss):
In the context of RL, since can then directly be used to train a function aprroximator (e.g., single or ensemble of neural networks) to approximate .
This accomodates the case of a noisy or unreliable oracle, in which case the Bradley-Terry model can be viewed as the generative model of the answers from the oraacle. When the oracle is reliable, more direct methods based on preference elicitation to recover the reward function have been studied.
Reinforcement Learning with Human Feedback loop
@kaufmannSurveyReinforcementLearning2024.
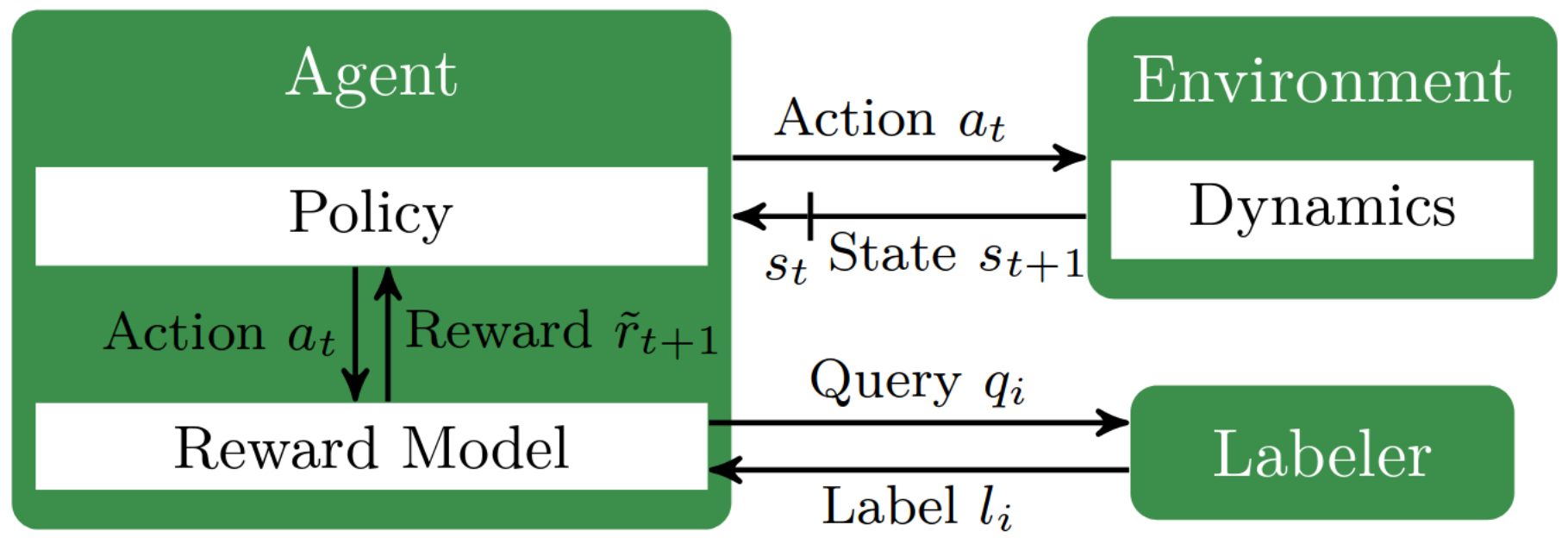
In the RLHF setting the learning agent needs to solve an RL task withouth having access to a reward function. To this end, the agent usually simultaneosuly learns an approximation of the reward function (via the assumed utility function) and an RL policy. Therefore, a generic RLHF alogirthm consists of repeating two phases:
- Reward learning, which divides in two sub-steps:
- generate queries to ask the oracle;
- train a reward function approximator with the answer provided by the oracle;
- RL training

For on-policy algorithm, such as PPO, only the recently generated transitions are used for training. For a DQN-like algorithm, lines 9-11 would be replaced by a loop where transitions are generated by a behavior policy based on the current estimate of the -function and the network is updated using mini-batches of transitions sampled from the replay buffer .
An efficient RLHF algorithm needs to overcome several difficulties:
- The oracle may provide various types of feedback;
- Informative queries need to be generated to minimize the efforts of the oracle, which is crucial when it is a human;
- Since the reward approximator is concurrently updated, the RL agent is trained in a non-stationary enviornment;
- How can you evaluate meaningfully the agent’s performance?
- Collecting human’s feedback introduces its own challenges, such as the question of suitable user interface and the associated issues of delay between query and feedback observation, or the feedback variability and reliability;
Also, in RLHF, since the oracle is a human, reducing the number of queries is crucial to limit the labeling cost.
Feedback types and their attributes
@kaufmannSurveyReinforcementLearning2024.
The feedback the oracle gives to the model can vary on many dimensions, in particular:
- Arity: This attribute describe whether an instance is evaluated in isolation (unary) or relative to other instance (binary, n-ary). Unary feedback is convenient for detailed and descriptive feedback but lacks grounding, putting the burden on the human to provide consistent feedback. Non-unary feedback always has an implicit grounding but relates to the instances being comparable. N-ary feedback, such as rankings, can provide more information than binary, but also put a higher cognitive burden on the labeler.
- Involvement: This attribute describe how involved is the labeler, it can either passively observe an instance, actively generate it or co-actively participating in its generation (co-generation). Usually, while less burdening, passive feedback often cannot match the information density of active feedback. It’s typical to combine both types to first initialize the reward model from active feedback, then refine it with passive feedback.
- Granularity: Feedback may differ on the granularity of the instance being evaluated: from whole episodes recordings, over partial segments to feedback on individual steps (i.e., states, actions, state-action pairs). Coarser granularity gives the human more context but pose credit assignment problems. Fine-grained feedback is much easier to learn from and simplifies credit assignment but it’s usually impractical or tedious for humans to provide.
- Abstraction: This describes whether feedback is given directly on raw instances, or abstract features of the instances. While feature-level information can be easier to learn from, extracting useful features is challenging.
- Explicitness: Humans may communicate explicitly for the purposes of feedback or implicitly as a side-effect of actions directed at other purposes.
- Intent: The assumed human intent can be important for feedback processing. A human may be evaluative, instructive or descriptive in their explicit feedback, while they are usually literal in their implicit feedback. Evaluative, instructive, and descriptive feedback is pedagogical in nature, aiming to teach a reward function, whereas literal feedback is a byproduct of a human actor’s efforts to optimize the reward function directly.
Common Classes of Feedback
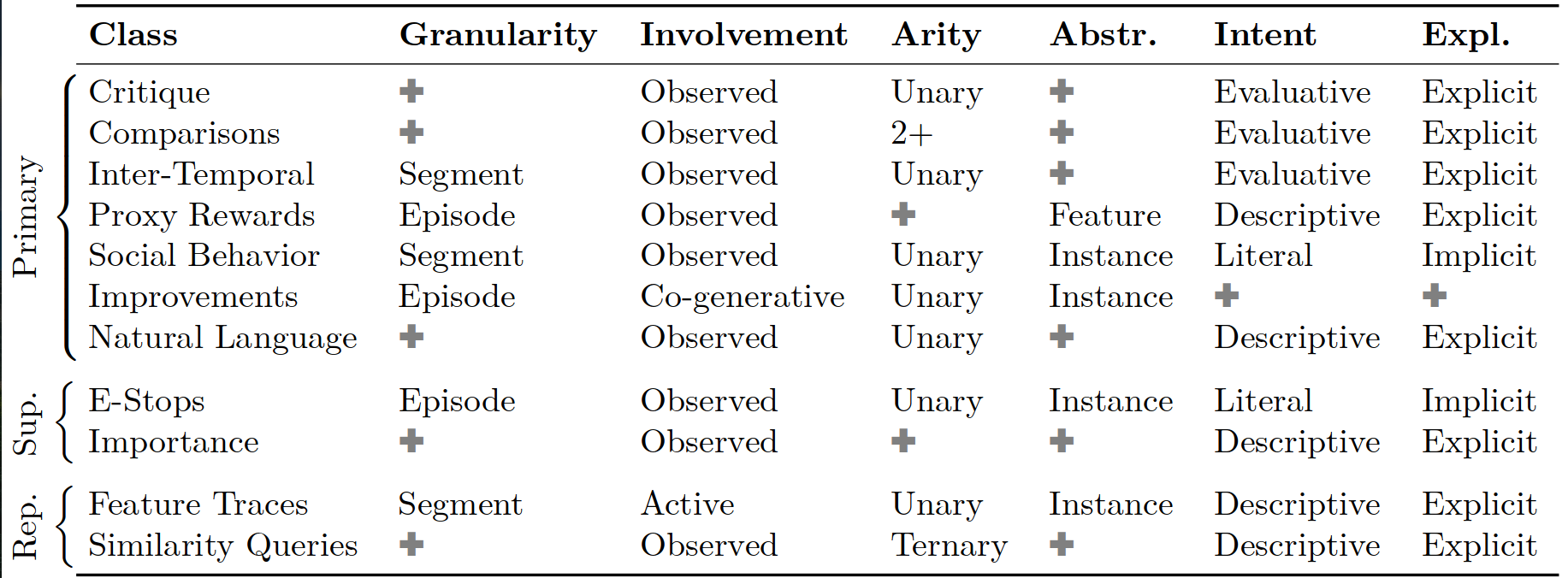
These are common feedback classes that can be used on their own to learn a reward model.
The primary ones are:
- Critique: It is the most direct type of feedback. In this setting, the human express their preference by directly critiquing an instance of agent behavior, often in the form of binary feedback. They can be binary feedback like good or bad actions, or can be multi-label feedback (@huangGANBasedInteractiveReinforcement2023 they map their labels to scalar values and then learn a reward model by regression).
- Comparisons: Binary comparisons and rankings are among the most common types of feedback. The human passively observe the behavior and gives relative feedback on multiple instances, explicitly with an evaluative intent. On whether to use binary comparisons or rankings, @zieglerFineTuningLanguageModels2020 note that for language tasks, a larger choice set can amortize the time needed for a labeler to get acquainted with the context necessary to understand a query.
- Inter-Temporal Feedback: In many real world environments, starting conditions or even the agent’s current task may vary between episodes. This makes the objective of the human labelers hard to compare different episodes. So, instead of comparing a set of instances with each other as in regular comparative feedback, inter-temporal feedback conveys relative judgments over different states in time within a single instance. These are explicit feedback on segments done while passively observing a single instance of the agent behavior with evaluative intent. It’s usually done on raw instances but any level of abstraction is possible. The two main ways of conveying this feedback are:
- Reward sketching: Introduced by Cabi et al., 2020, involves users sketching a visual representation of the reward function over time. This type of feedback which can be given by sketching a graph with the mouse while watching a behaviour recording, provides intuitive, per-time-step reward annotations.
- Inter-temporal preferences: Introduced by Abramson et al., 2022, humans in this settings give feedback on multiple points during the trajectory, indicating whether an agent is progressing or regressing w.r.t. the goal. One potential downside of this feedback type is that labelers may tend to give preferences that rewards short-term actions that are easy to judge, failing to communicate long-horizon preferences.
- Proxy Rewards: Proxy rewards are partial or inaccurate reward functions that convey information about the task the agent is supposed to complete but may not induce optimal behavior. The defining features of this type of feedback is that the labeler passively observers and give feedback explicitly of a feature-level with descriptive intent. He & Dragan, 2021 for example use this form of feedback by using proxy reward functions, i.e. preliminary reward functions that might not cover all edge cases, to guide the agent towards learning the actual reward function.
- Social Behavior: This type of feedback consist in implicit feedback given by human observant on segments with respect of a singe instance by doing facial or gesture reactions.
- Improvements: Usually after observing an entire episode at the instance level, the human observe and then demonstrates the behaviour resulting in co-generative involvement. They can be post-facto, called corrections, and improvement while acting, called interventions.
- Natural Language: Natural language feedback can be given on any granularity and at any level of abstraction. Its defining features are that it is given explicitly in the context of a single observed behavior with descriptive intent.2.
In addition to using any of the previously described feedback types in isolation, combining multiple feedback types i both possible and often advantageous. The three main ways of combining feedback are:
- A two-phase setup consisting of initialization and refinement;
- Integrating a primary feedback with a supplementary one;
- Merging multiple primary feedback types;
Pipeline from Ziegler et al., 2020
@zieglerFineTuningLanguageModels2020.
The Reinforcement Learning with Human Feedback pipeline consists in three steps:
- Supervised Fine-Tuning;
- Preference Sampling and Reward Learning;
- RL Fine-tuning;
Supervised Fine-Tuning
This phase consists by fine-tuning a pre-trained LM by supervised learning with high-quality data for the downstream task(s) of interest to obtain a model .
Preference Sampling and Reward Learning
In this second phase the model is prompted with prompts , to produce pairs of answers . These are then presented to human annotators that express preference towards either or , these are denoted as where is the preferred option among .
The assumption is that we can model these preferences using a model that we don’t have access to.
There are a number of different approaches to model human preferences, with the Bradley-Terry (BT, @bradleyRankAnalysisIncomplete1952) model being a popular choice. This stipulates that the human preference distribution can be written as:
Assuming access to a dataset of comparison , sampled from , we can parametrize the reward model and estimates the parameters via maximum likelihood.
Framing the problem as a binary classification we have the negative log-likelihood loss:
where is the logistic function.
For LMs is initialized from the model with the addition of a linear layer on top that produces a single scalar prediction for the reward value.
RL Fine-tuning
During this phase, the learned reward function is used to give feedback to the LM. In particular, the following optimization problem is formulated:
where is a parameter controlling the deviation from the base reference policy , which is . In practice, also the language model policy is initialized to .
The rightmost part is an important added constraint which prevents the model from deviating too far from the reference distribution on which the reward model is trained and is accurate for. This also keep the generation diversity and prevents the mode-collapse to high-reward answers.
Due to the discrete nature of Language Modeling, this objective is not differentiable and is solved trough Reinforcement Learning.
A common approach is to construct the reward function as:
and is then maximized using PPO (@schulmanProximalPolicyOptimization2017).