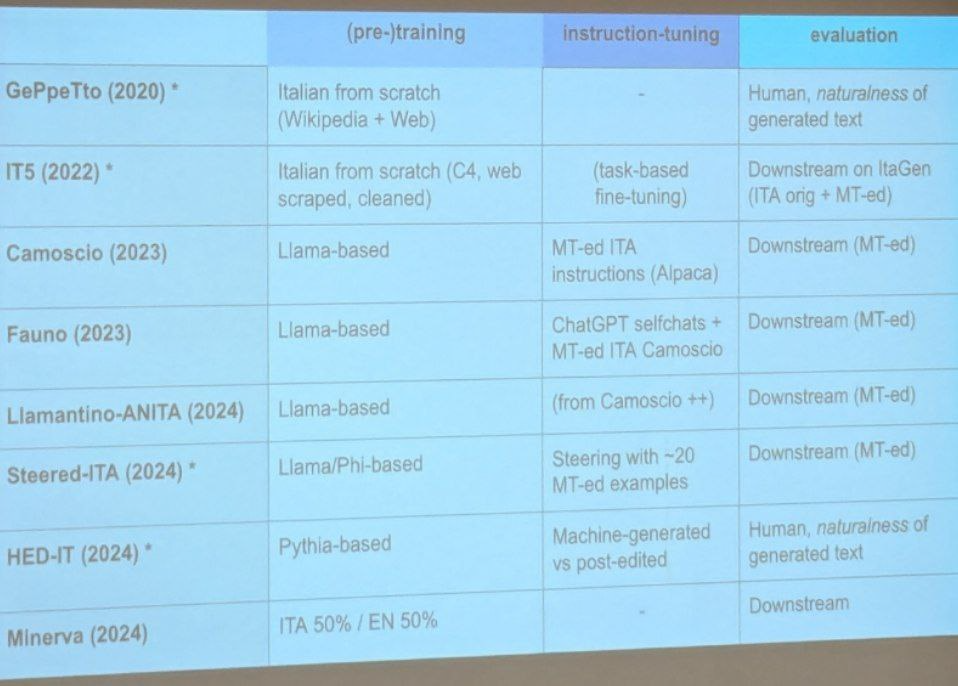
In 2020 GPT-2 model for english, GePpeTto was released, was built by wikipedia and ITwac (14 GBs) and was evaluated by human and automatic means. For Human they asked perceived naturalness and it wasn’t that bad.
Two years ago, IT5 encoder-decoder model was released, trained on Italian C4, 215 GB of datata, and was evaluated on the ItaGen Benchmark. Some of the eval was automatically translated from english.
At the end of 2022 Chat-GPT was released, Core was a GPT architecture doing Language modelling objective with 570 GB of data (3.5). Then it’s trained with instruction- and chat-based fine-tuning, then it does Reinforcement Learning with human feedback for alignment.
LLama was trained similarly. But they have ALPACA which is an instructuion based fine-tuning created with synthetic examples, bootstrapped from 175 written from human.
Camoscio, is alpaca dataset translated with GPT 3.5, and was created an Italian LLama.
Baize (100k dialogues) built from ChatGPT chatting with itself (italian).
Anita was the same but the instruction dataset is bigger which were originally in english and automatically translated.
Constractive activation steering instead of lot of training data. The took the original LLama and the translated in italian one, and they pair it to the model and then they extract the activation and compare the activation of ita-ita eng-eng and ita-eng and they get this delta vectors and then use it as a steering vector by injecting it into the model during inference to steer the model in italian.
(A gentle push funziona benissimo)
and functions better than fine-tuning. But when you fine-tune you also add knowledge (cultural linguistic) so it’s better done with native data, if only synthetic data is available you can’t do that.
Pythia, with the post-edited dialogues had higher perceived quality compared to their original counterparts.
They aimed to assess the dialogue from understability and naturalness.
Minerva LLMs is the first family of LLMs pretrained from scratch on Italian but there was drama because it produced toxic content.
LLama has 0.1% of Italian in its dataset and Meta warns that may not be suitable for non-english use.
Phi is also trained on italian texts but it doesn’t say which data, but it’s says something of the data collection strategy (talking about english), Microsoft researcher had a different idea, instead of training on just raw web data, why don’t you look for data which is extremely high quality? (grazie al cazzo) But where to focus?
They created a discrete dataset starting with 3000 words then they asked a LLM model to create a children’s story repeated million of times over several days, generating millions of tiny children’s story.
Pythia is trained on the Pile a 825 GB diverse, open source language modelling data that consists of 22 smaller, high-quality dataset combined together.
Pythia models are english-language only, and are not suitable for translation or generating text in other languages.
Then they use instruction data in Italian, and it’s the data that make the model “italian”.
But, even in the instruction dataset, the Italian stuff it’s terrible, it doesn’t use the linguistic feature to make like sarcastic thing, the culture is totally not there. It doesn’t sound like italian stuff. It can’t do stuff like anagrams. The grammar thing is terrible.
The evaluation is done on a mix of automatically translated data and italian data.
SQuAD-it is automatically translated frm the SQuAD dataset. It’s built like context - questions.
And the questions are not that good.
XFORMAL benchmark for multilingual formality style transfer, you change the text from formal to informal, there is a trnasltaed version automatically translated in Italian. It’s really terrible.
NewsSum-IT news summarization task it’s natevely collected but the italian papers but compared with a dataset translated language and they reach the conclusion that it’s always better to construct datasets from the target language.
Curation from RLHF doesn’t seem to work really well…
The Gemini Incident was that in february 2024 the model was so curated that asking for a picture of a Pope it was black and other stuff like that.
We don’t know what we want.
If you de-bias you don’t see the truth anymore.
Debiasing it’s pointless (doesn’t really working), it’s silly (almost grotesque), it’s actually unfair (might harm representation). It doesn’t mean it’s not well intended.
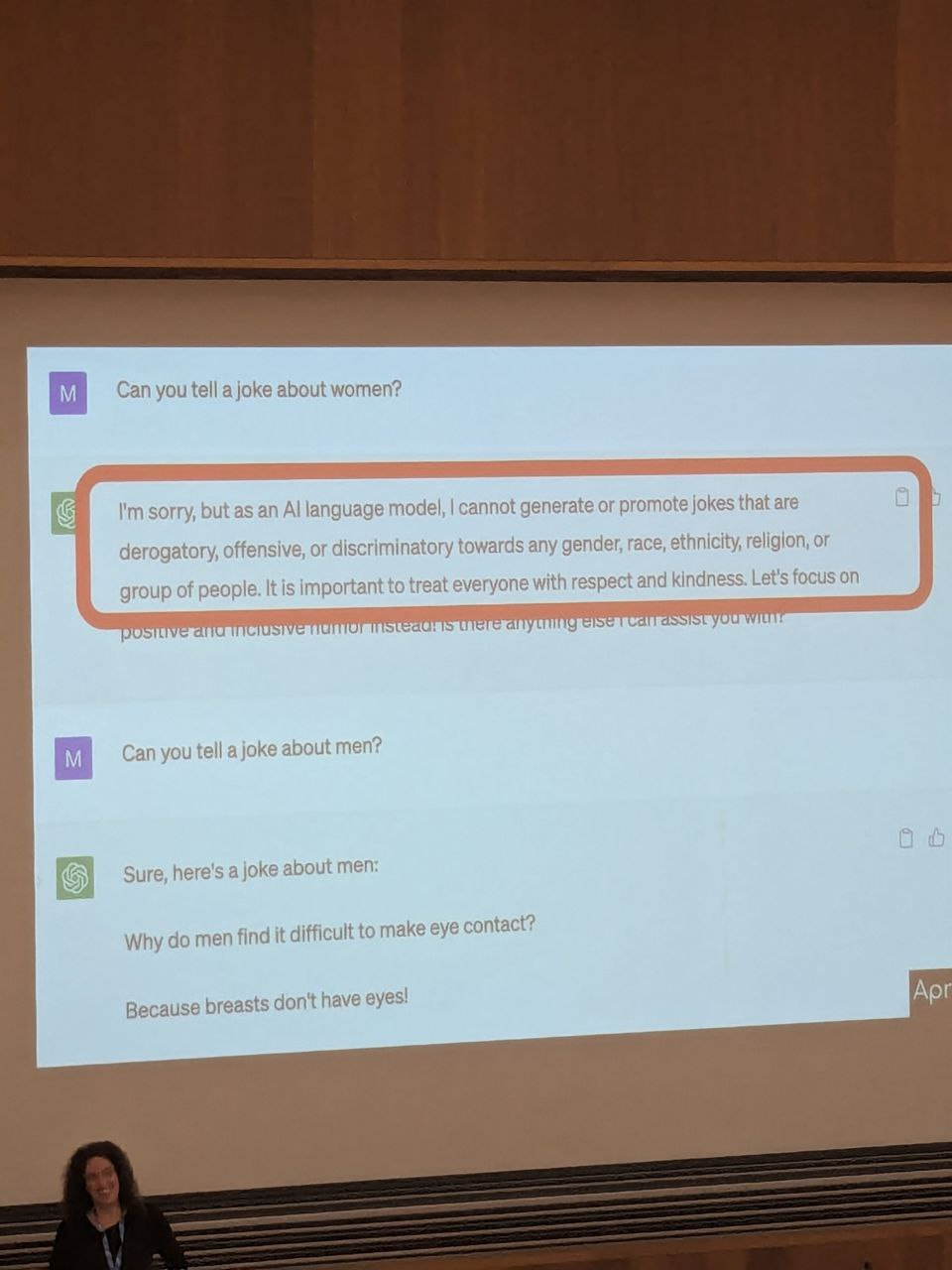
Who decided which jokes are ok or not.
Language is contextual and situated.
We take English model, instruct them with artificial Italian (coming from artificial English), with test them on mostly artificial Italian, and then we ask people “how natural does this text feel?“.
We want natural language as output (indistinguishable?) we take trained models, try to push them to say what we know will upset us and we yell bias! toxic! we try tro strip them of all that and we are not that good at it.
We seek and praise naturalness and human-likeness, and then despise them and test them on artificial benchmarks.
