Classical Deep Architecture can be seen as a Bayesian network / using Bayesian formalism. Internal score (logits) are not to be used as a Bayesian estimate.
From Classical Probability to Bayesian Theory
Probability of a given event is the probability of that event w.r.t. of all possible events.
is the sample space (all that can potentially happen)
the sigma algebra (Tribù) of events
the probability measure, which:
- ,
is the space of all events
Events are all the combination of outcomes you’re interested in.
Mass Probability Function
It is to provide the description of the probability we are interesting in.
The probability mass function of a fair die is:
From Discrete to Continuous distribution
In the continuous case we have to define a mass function density:
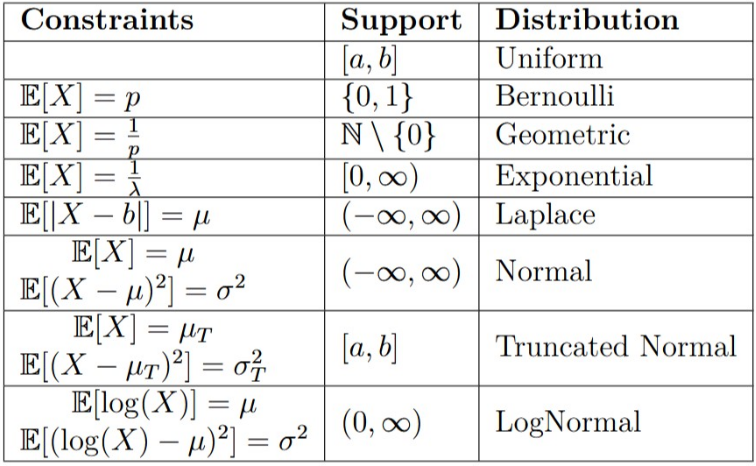
The first part is the interval, the second part is the density. Some famous density function are uniform distribution, the log-normal or the Gaussian.
Shannon Entropy
Entropy is a measure of the amount of knowledge. You can use the Shannon entropy to find the family of distribution for your data.
Definition. Given a discrete random variable , with possible outcomes the Shannon Entropy of is defined as:
Given a random variable with probability density function whose support is the differential entropy (or continuous entropy) is defined as:
where the base of the logarithm can be chosen freely. Common choice include or .
A maximum entropy probability distribution has entropy that is at least as great as that of all the members of a specified class of probability distributions.
Density in
We can look the shadows on each dimensions. Ogni dimensione è una random variable:
This doesn’t let you study co-variance. You need to study simultaneously in every dimension, so, we are going to take a strong assumption, that the directions are independent.
Central Limit Theory
You can ensure that anything becomes a normal distribution by doing a lot of sampling.
Every time you take multiple variables and average it or sum it, you get a gaussian distribution. 1 die has a uniform distribution, if you take 2 and average them you get a gaussian.
Suppose is a sequence of i.i.d. random variables with and . Then, as approaches infinity, the random variables converge in distribution to a normal .
Random Variable
possibilities and event can be too complex, sometimes intractable.
A random variable is a measurable function, which moves the original settings to a easier one, while maintaining some properties of the original space.
e.g.
e.g. If I get 7 by summing two dice I win, otherwise I lose. I don’t care about the space containing all the probabilities, I just want to work with binary possibilities: I win or I lose.
Conditional probability
The probability of the two events happening at the same time is the probability that A after B happens once B happened.
What is the probability of getting a 2 on a D6, knowing that we got an even number?
Conditional Probability works also for continuous r.v.
If A and B are independent then . e.g. what is the probability of getting a 2 on a D6 knowing that I got a brown die.
Bayesian Formula
Posterior is , is the likelihood, is the Prior, and is the evidence.
Likelihood, plauisibility of given a certain outcome when my hypothesis is true.
The prior is what we believe, and likelihood is where we are right.
Likelihood is the probability of observing the data given the current weights.
Likelihood and loss function are almost the same thing, they are strongly related, we want the model to maximize the likelihood by minimizing the function of the likelihood called loss function.
The prior in a NN setting is the starting weights.
The posterior is the set of final weights given the input data.
The likelihood is: are my weights given the data?
The second part is the density function, the density of the output.
By definition the likelihood of a given models, given new data, is the “probability” of obtaining those data from the weights of the model.
We assume that each data is independent and identically distributed. And we can rewrite like on the right.
If you have a good prior bayesian learning is very good otherwise bad, you need a lot of data to correct.
Predictive Posterior Distribution
We are modeling , not like we do in the posterior which are the weights given the dataset. In inference we plug in the network and we got . We are modeling , the distribution of the predictive posterior.
Artificial Neural Network
Copy Anatomy of a feed forward ANN.
We need a non-linear f because if we don’t have it’s just a linear matrix multiplication and addition and that could be collapsed to a single layer.
The bias is optional.
It acts as a threshold under which the next layer doesn’t change that much. It helps stabilizing.
Recipe of ANN
- A set of hyper-parameters and trainable parameters.
- Some non linearity.
- An objective function (cost/loss)
- An optimization method
- Sufficient data
The family of neural networks is dense in the function space, any kind of function can model any function.
Feed forward networks with non-polynomial activation functions are dense in the space of continuous functions between two Euclidean spaces, w.r.t. the compact convergence topology.
ANNs training in supervised learning
We need a dataset we need to define a measure which compares the quality of the predictions, e.g. MSE.
We also need a way to teach the model how to update weights. We use the gradient, i.e. the best direction of update for the objective function.
Computing the derivative is usually intractable, so we use back-propagation algorithm.
Known Losses
RMSE for regression works really well
Cross Entropy for classification
The loss is the key of NN.
Reconstruction
we use RMSE