@scartonLearningSimplificationsSpecific2018
Text simplification (TS) is the task of modifying an original text into a simpler version of it.
Traditionally, work on TS has been divided in Lexical Simplification (LS) and Syntactic Simplification (SS).
Resources on TS:
- Wikipedi-Simple, collection of Wikipedia articles and their simplified versions created by volunteers;
- Newsela Article Corpus, news simplified for various specific audiences following the US school grade system.
Newsela, being simplified by professional have better simplifications, and each original article has been labeled indicating its corresponding grade level and each article may have multiple simplification based on the target audience.
System Architecture
The approach adds an artificial token to both training and test instances that encode information regarding the simplification:
- to-grade: the token corresponds to the grade level of the target instance;
- operation: the token is one of the four possible coarse-grained operation that transforms the original into the simplified instance:
- identical: an original sentence is aligned to itself, no simplification performed;
- elaboration: an original sentence is aligned to a single, rewritten simplified sentence;
- one-to-many: split an original sentence into two+ simplified sentences;
- many-to-one: merge two+ original sentences to a single simplified sentence;
- to-grade-operation: concatenation of the two above token type.
Of course, while to-tokens are available at test time by knowing to which audience we want to propose the text, the operation type can’t be known. So, to remedy that, a simple Naive Bayes classifier using nine features predicts the operation type. Features: number of tokens, punctuation, content words, clauses, ration of: number of verbs, nouns, adjectives, adverbs, connectives to the number of content words.
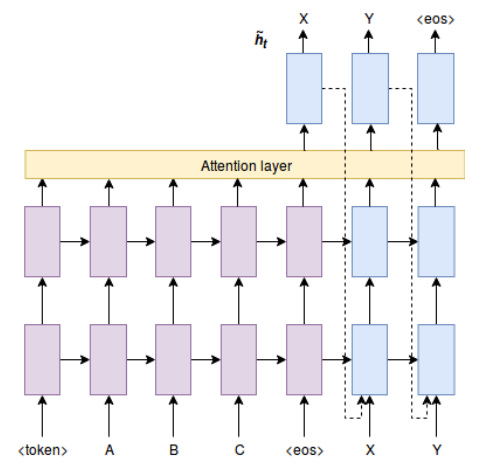
The Neural Architecture consists of an encoder-decoder, each of 2 LSTMs layers with size 500 and a recurrent dropout of 0.3. A Global attention layer is used.
A model is trained for each dataset constructed with different artificial tokens for 13 epochs, than the best model is selected by perplexity on the dev set.
Results
Results using BLEU, SARI and Flesch.

The best model is the one built with the to-grade-operation token with gold operations annotations. While the model with predicted operations still outperform the baseline, they lag behind their counterparts built with gold operation. In a real world scenario, the best model is the to-grade model, given the low performance of the predicted operations systems.
The main advantadge of thi system is that a user can inform their grade level and retriev a personalized simplification.

Example of different simplification.
Zero-shot
The model has been tested on couples of original grade to target grade that didn’t exist on the original dataset outperforming the baselines, showing the effectiveness of the to-grade method.