Fuzzy Logic
Fuzzy sets are a type of set where membership cannot be established with certainty but trough a continuous function.
Different types of Uncertainty
Uncertainty analysis in Machine Learning begins with the formal definition of the uncertain quantities involved in the modelling problem.
Aleatoric uncertainty can’t be reduced while epistemic can be reduced.
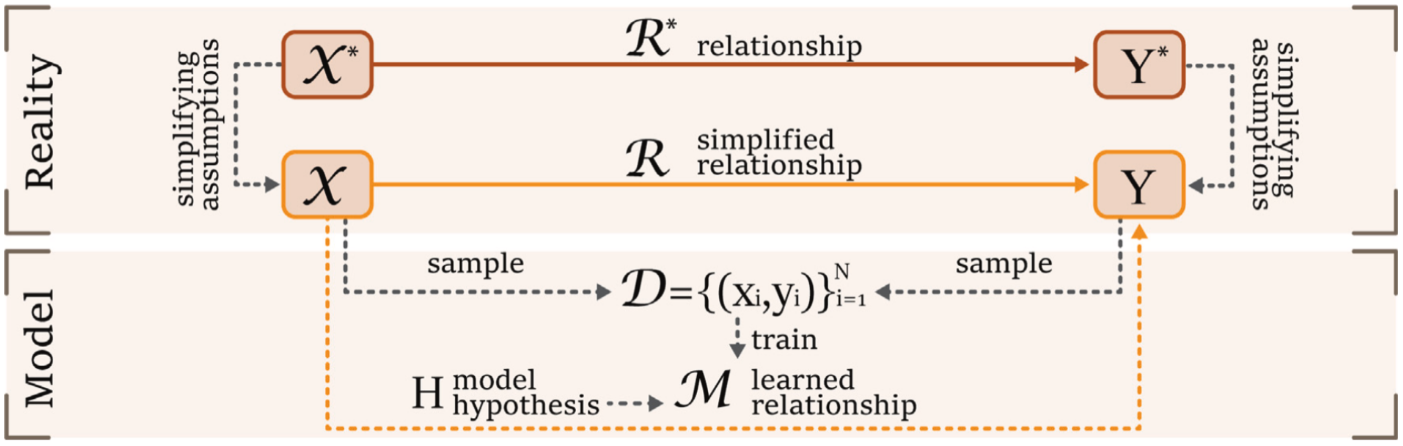
The goal of the mathematical modeling process is to estimate the relationship using an approximating model constructed from a dataset and as et of hypothesis .
Approximating model:
Sample of inputs and associated values:
Set of trainable and non-trainable parameters:
Aleatoric Inherent Uncertainty
is usually not deterministic, and the source of uncertainty is a property of the relationship/reality and thus can’t be reduced by providing more data or improving the models. The Aleatoric Inherent Uncertainty can be considered a function of both the input and the relationship :
Contains randomness, we can’t do nothing about it.
Example: Consider a relationship which associates an integer with the value given by the sum of six-sided dice. is inherently random, since the same input may correspond to different outputs .
Aleatoric Experimental Uncertainty (or Noise)
It refers to the variations in information content caused by the acquisition process like artifacts, errors in labels, measurements errors, experimental settings, etc.
This uncertainty affects both the input and output, making the problem almost mathematically intractable. But i is possible to change the perspective of the problem:
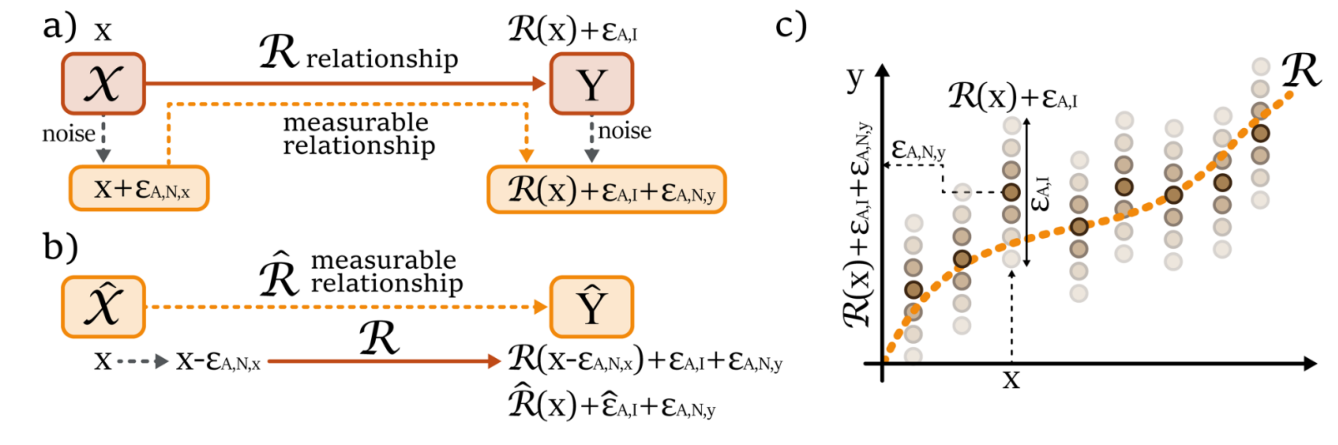
The original would be:
the shift would be:
e.g.
We use two rulers each have it’s own uncertainty. We assume the first measure is exact, all the error is translated in the second measurement, plus the error propagation of the first.
Aleatoric Model Uncertainty
Aleatoric uncertainty can also be generated by the model during the inference process. This is due to the pseudo-random propagation of rounding errors on a machine.
Aleatoric Model Uncertainty () is often negligible compared to the other components of aleatoric uncertainty. We will consider only the inherent and the noise.
Epistemic Uncertainty
Epistemic Uncertainty can also be called subjective, reducible or systematic.
Can be induced by the a priori choice of hyper-parameters characterizing the model or by a finite amount of available data.
Since this uncertainty is due to a lack of knowledge it can be reduced by improving the model hyper-parameters or by increasing the size of the dataset (i.e. it’s the reducible part of total uncertainty)
The approximated model is
and are the representation of the whole space. We are assuming to train with infinite data.
We focus on the model’s parameters, we have which are the trainable parameters (weights and biases), and which are the non-trainable parameters, like which model we are using, the model’s geometry, the loss function, and other hyper-parameters.
We fix hyper-parameters , we have to choose the optimal which is fully characterized by its trainable parameters .
We want to find which is the one that minimize the loss. Formalizing the problem:
we obtain the optimal bayesian predictor:
with fixed, established hyper-parameters and optimal trainable parameters.
Epistemic Model Uncertainty
Even with optimal trainable parameters and even assuming a null aleatoric uncertainty (inherent + noise) there could be a discrepancy between the optimal reality and the model outcome: .
The discrepancy between the Optimal Bayesian Predictor and the reality is called Epistemic Model Uncertainty:
even with an infinite amount of data, when you project some amount of information in the problem (you choose a structure, you choose a loss function, etc.), you will **always approximate the reality**. You will never reach the reality. Thus, the $\epsilon_{E, M}$ can be reducible, but cannot be deleted.
So the Optimal Bayesian Predictor is the best approximation of reality we can get.
Epistemic Approximation Uncertainty
The approximating model requires full knowledge of the space , which is usually not available to the experiments and we have to use a dataset. Information about the space is provided by a sample called , the training dataset:
Once the hyper-parameters are established , the goal is to induce an optimal trainable parameters on dataset .
is the approximation of optimal trainable parameters. Which are obtained trough the minimization of the loss/risk:.
is an approximation of . The discrepancy depend on the quality and the number of data available and is called the Epistemic Approximation Uncertainty ():
We obtain an empirical model
where the trainable parameters are the best one obtainable on your data-set .
The discrepancy between and depends on the quality and the number of data available and is called the Epistemic approximation Uncertainty()
This is also called interpolation uncertainty and can be reduced by improving quality and size of the dataset.
Balancing Epistemic Uncertainty
The empirical distribution obtained from and used to train the model, imperfectly mimics the real underlying distribution on (i.e. )
Increasing the dataset size improves the approximation, reducing the Epistemic Approximation Uncertainty but cannot reduce the epistemic model uncertainty.
Increasing the complexity of the model (increasing the number of trainable parameters ) improves the model’s ability to approximate a deterministic relationship .
For ANN, the Universal Approximation Theorem ensures that a sufficiently complex Neural Network can perfectly approximate every relationship .
However the increasing complexity requires a huge amount of data to be trained on, resulting in a dramatic increase in Epistemic Approximation Uncertainty .
Summary of the uncertainties
Here is the representation of reality that we would like to reach. It’s always affected by the inherent aleatoric uncertainty and the noise. This are non-reducible
Here, we have the epistemic model uncertainty that is related to the choice of the model by fixing hyper-parameters, geometry etc. However, by having an infinite amount of data we find the optimal bayesian predictor, which has the best set of trainable parameters.
And here we also have the “problem” of the amount of data, because we can only train our model with sampling from reality. (Epistemic Approximation Uncertainty)
- The optimal bayesian predictor is the best approximation of R on the whole space
- Empirical model best approximation of predictor on the dataset D.
The equation that contains the full relationship between the actual model and the reality can be summarized as:
Can be summarized in the sum of the aleatoric uncertainty and the epistemic uncertainty (predictive posterior uncertainty). However uncertainties are not additive terms, because they must be considered as nonlinear functions, so they also have a multiplicative component. Our aim is to reduce uncertainty.
Techniques to handle Uncertainty
Are divided in:
- Intrusive (By design);
- complex implementation;
- computationally expensive;
- effective;
- Semi-Intrusive;
- effective and easy to implement;
- computationally expensive;
- Non-Intrusive (Post-hoc);
- easy implementation;
- computationally less expensive;
- inferior performances;